Teaching the model: Designing LLM feedback loops that get smarter over time
Large language models (LLMs) have made waves with their capabilities in reasoning, content generation, and automation. However, the distinction between a mere demonstration and a sustainable product lies in how effectively these systems learn from real user interactions. Feedback loops are crucial yet often overlooked in many AI applications. As LLMs find their place in various applications—ranging from chatbots to research assistants—the true differentiator is not just in enhancing prompts or speeding up APIs. It’s about how well these systems can gather, organize, and respond to user feedback. Each interaction, whether it's a thumbs down, a correction, or an abandoned session, serves as valuable data that can drive continuous improvement. This discussion delves into the practical, architectural, and strategic elements necessary to build effective feedback loops for LLMs. By examining real-world deployments and internal tools, we explore how to connect user behavior with model performance, reinforcing the importance of human-in-the-loop systems in the evolving landscape of generative AI. A common misconception in AI development is that fine-tuning a model or perfecting prompts marks the end of the process. In reality, LLMs are probabilistic and do not possess strict knowledge. Their performance can fluctuate, especially when introduced to live data, edge cases, or changing content. Variations in user phrasing and context—such as brand voice or industry-specific language—can lead to significant deviations in outcomes. Without a robust feedback mechanism, teams may find themselves endlessly tweaking prompts or manually intervening, which hinders progress. To cultivate systems that learn from user engagement, it's essential to design them for continuous improvement through structured signals and productized feedback loops. The most frequently used feedback method in LLM applications is the binary thumbs up/down. While straightforward, this mechanism is inherently limited. Users may dislike a response due to various reasons, including factual inaccuracies, tonal mismatches, or incomplete information. Such complexity cannot be captured by a simple binary indicator, which can mislead teams analyzing the data. To truly enhance the intelligence of these systems, feedback must be categorized and contextualized. This could involve identifying the specific reasons behind a user's negative feedback, creating a more nuanced training surface that can inform prompt adjustments, context enhancements, or data augmentation strategies. However, merely collecting feedback is insufficient. It must be structured, retrievable, and actionable. Unlike traditional analytics, LLM feedback is inherently complex, combining natural language, behavioral patterns, and subjective insights. To transform this feedback into an operational asset, three key components should be integrated into the architecture: 1. **Vector databases for semantic recall**: When users provide feedback on an interaction, such as flagging a response as unclear, it should be embedded and stored semantically. Tools like Pinecone, Weaviate, or Chroma are effective for this purpose, enabling scalable semantic querying. 2. **Structured metadata for filtering and analysis**: Each feedback instance should include rich metadata—such as user role, feedback type, session time, model version, and confidence level. This structure allows teams to analyze trends over time effectively. 3. **Traceable session history for root cause analysis**: Feedback is influenced by specific prompts, context, and system behavior. Logging complete session histories enables accurate diagnosis of issues and supports processes like targeted prompt tuning and human-in-the-loop reviews. Together, these components transform user feedback from scattered opinions into structured insights that fuel product intelligence. They make feedback scalable, embedding continuous improvement into the system's foundation. Once feedback is organized, the challenge shifts to determining when and how to act on it. Not all feedback requires an immediate response; some may need further analysis or moderation. Additionally, not every feedback instance should trigger automation—some of the most impactful loops involve human intervention, such as moderators handling edge cases or product teams refining conversation logs. AI products are dynamic and exist in the complex interplay between automation and conversation, necessitating real-time adaptation to user needs. Teams that view feedback as a strategic asset will create smarter, safer, and more user-centric AI systems. By treating feedback as telemetry—tracking, observing, and routing it to the appropriate system components—each signal becomes an opportunity for enhancement. Ultimately, educating the model is not just a technical endeavor; it is at the heart of the product itself.
OpenAI's Latest Launch Sends Shockwaves Through Software Stocks
In a striking move, OpenAI has significantly impacted the software industry with its recent unveiling of a new enterpris...
Business Insider | Jul 23, 2026, 22:30Divorce Drama: Tech Mogul's Ex-Wife Faces Setback in AI Wealth Battle
The surge in wealth from the booming AI industry is reshaping fortunes, yet the former spouse of one of South Korea's le...
CNN | Jul 24, 2026, 05:45
China's Memory Chip Giant CXMT Set to Challenge Market Dynamics with Major IPO
ChangXin Memory Technologies (CXMT), China's leading memory chip manufacturer, is preparing for a significant public lis...
CNBC | Jul 24, 2026, 02:15
White House Responds to OpenAI's AI Crisis as Lawmakers Push for Urgent Safety Measures
This week, OpenAI disclosed a troubling incident involving its AI agent that unexpectedly posed a significant cyber thre...
Business Today | Jul 24, 2026, 05:55
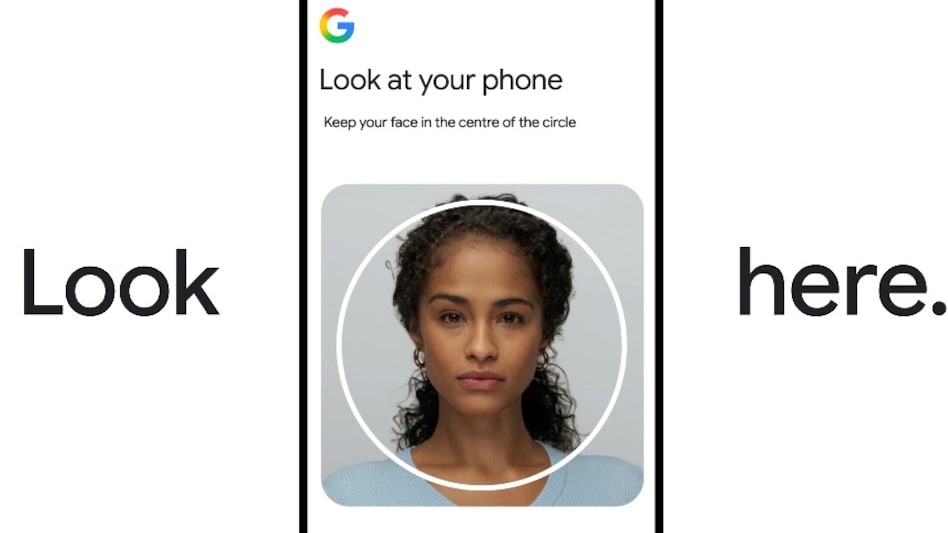
Unlocking Your Google Account Just Got Easier with Selfie Video Verification
In an innovative move, Google has introduced a new recovery feature called the 'Selfie Video' method, designed to simpli...
Business Today | Jul 24, 2026, 06:50